

Beyond the Debugger: A Comprehensive Guide to Debugging Go Applications
Not all bugs are created equal. Some may be easy to pinpoint and eliminate with the help of a debugger. Others might be subtle or infrequent, and tracking them down is like searching for a needle in a haystack. Choosing the right debugging technique can significantly raise the chance of success while reducing the time to get there.
Table of contents
Everyone knows that debugging is twice as hard as writing a program in the first place. So if you’re as clever as you can be when you write it, how will you ever debug it?
–Brian W. Kernighan, in The Elements Of Programming Style
I must admit: I use a debugger like, once in a blue moon1. I'm more the “sprinkle some Printf statements across the code” type of troubleshooter. (I even created an ad-hoc debug logging package called what with progress- and state-dumping statements that completely vanish from the production binary, leaving no way for unintentionally leaking sensitive data.)
However, whether or not to use a debugger isn't a question of style or preference. You might be fine with having tests and some extra logging statements in one codebase, only to discover that in another codebase, you'd be completely lost without a daily dose of debugging.
So if you want to thrive at debugging, you need an array of debugging (and pre-debugging!) strategies and techniques, starting with being prepared well.
Precautionary steps
The easiest bug to fix is the one you avoid. The second-easiest bug is the one you can catch early. A few measures taken in advance can make a big difference.
Write clear, readable, and debuggable Go code
Debugging starts well before starting a debugger.
The moment you start thinking about a software system to write, your thoughts and decisions influence how debuggable your system will become. so get clear, very clear about the Problem to solve. Then use this clarity to write clear code.
Cumulated experience has created plenty of software development paradigms, methodologies, principles, and techniques to produce low-bug, and easy-to-debug software, including:
- All concepts that encourage loose coupling. This includes all layered architectures, such as Clean Architecture or Hexagonal Architecture.
- The SOLID meta-principle, made of the Single Responsibility principle, the Open-Closed principle, the Liskov Substitution principle, the Interface Segregation principle, and the Dependency Inversion principle.
I'm not going to go into details here; these topics fill entire bookshelves and deserve to be studied separately.
How to write clear code? Start simple and follow Go's idiomatic practices, such as:
- Keep functions small and focused
- Choose short but descriptive names
- Write code as self-explanatory as possible (“Clear is better than clever”)
- Write package- and function-level documentation comments
- Prefer early returns over deeply nested if-else constructs
- Avoid global variables
- Leverage Go's interface system for flexible and modular code design
- Be consistent in your way of programming, but ensure to stick with the rules set by your team
There are many more great practices; I'll leave it as an exercise to you to discover and internalize them.
Pro tip: Follow the “Boy Scout Rule” and leave code clearer than you found it.
Use Test-Driven Development as a debugging strategy
Write tests to express expected behavior before implementing this behavior as code.
Two reasons:
- Tests validate your understanding of the problem
- Tests help to catch bugs early and avoid regression
Specifications written in plain English are important, yet they don't connect to the code written. Unit tests, integration tests, and end-to-end tests are the bridge between spec and code. A well-written test is almost like a formal specification of the code, without the need to use a formal specification language. You can stay within the language you know to describe what the code is expected to do.
Remember: Tests run automatically for you; debugging must be done manually.
Ensure to cover as many edge cases in your tests as possible, as these cases are a typical source of bugs that tend to pop up three weeks after the code was rolled out to production. Employ all kinds of tests your language offers: Go provides unit tests right out of the box, including table-driven tests, fuzz testing, golden test files, and more. Ignore these useful test strategies at your own peril.
Once all tests are in place, you'll enjoy more freedom at changing the code. Tests serve as permanent guardrails that let you make changes safely, knowing that the tests immediately flag any change that breaks the intended behavior. Remember: Tests run automatically for you; debugging must be done manually.
Strategic logging: Peek inside your code's black box
Log output is invaluable for debugging. If log statements have been properly placed, they produce a timeline of events that lead to a given outcome, including the bug you are hunting down.
As a general rule, place log statements everywhere except for public packages, as you don't want to impose a particular logging style or library onto your package's clients. Logging remains the duty of an application and its internal packages.
However, placing log statements is not an easy task, as you have to balance information against overhead. There are no strict rules, so it's up to you to find a good balance. The existence of different “schools” of logging doesn't make this task easier. Moreover, logging is not purely meant for debugging assistance. Logging can catch issues that aren't related to coding bugs, such as malicious login attempts. This increases the number of decisions for good log statement placing.
In any case, the very minimum of logging should cover:
- Any errors and validation failures that your code produces or some library code reports.
- Security-related application events, such as authentication and authorization or data flow into or out of the application.
Ensure that every log statement provides enough context to be useful. Start with these “Five Ws”:
- When did something happen? (Time stamp)
- What is happening? (Type, severity, description)
- Where did it happen? (Application ID, service name, code location)
- Who did this? (Human or machine user)
- Why does this happen? (Especially in failure cases)
The little story of a context-free, low-level error in this Spotlight shows why context is crucial.
For more logging advice, see OWASP's Logging Cheat Sheet.
A Go-specific tip: Use Go's slog package for all non-trivial applications. Sooner or later, you'll appreciate the structured log output and the pluggable backends that support automated log processing.
Ad-hoc logging techniques for debugging
Logging is a strategic decision that should be made when writing the code. But sometimes you might hunt down a bug and discover that the code that seems most interesting for your troubleshooting produces insufficient, if any, log output. Now, if this lack of output indicates a missing log statement, add it and go on troubleshooting.
Some logging, however, would only be needed to troubleshoot a particular situation; the log output would not add value to the log file in general.
Here, you can deploy what I call “ad-hoc logging” statements. This kind of logging tracks your code at an arbitrarily fine-grained level but won't interfere with the rest of your logging, because you either disable or remove those ad-hoc log statements after the bug is found and fixed. That is:
- Place temporary log statements where you need to get more information
- Compile and re-run the steps to replicate the error
- When you're finished, disable or remove the temporary log statements
This technique is particularly appealing with languages like Go where compiling takes no time.
The most effective debugging tool is still careful thought, coupled with judiciously placed print statements.
– Brian W. Kernighan
Debugging sometimes requires logging sensitive data. To avoid that such data ever appears in production logs, I wrote and use what, a package that uses compile tags to switch ad-hoc logging statements on. This way, no sensitive logging can unintentionally escape into production.
To conclude this section, spreading a few more log statements across problematic code can greatly help to pin down a bug.
When bugs strike: debugging Go applications
The first rule of troubleshooting: Always look for the root cause.
Once you discover, or get notified of, a bug, refrain from jumping head-first into debugger sessions. My first rule of troubleshooting a bug: Always look for the root cause. Otherwise, you would only cure the symptoms and allow the bug to pop up again.
- Examine log output
- Identify the conditions under which the bug occurs.
- Strive to get a reproducible test case, ideally from the person who raised the bug (as they already know more about the bug's circumstances than you do at this point)
- Talk to your teammates, coding buddies, or anyone involved in the project. A second pair of eyeballs is sometimes worth gold.
Bugs are tricky. Some bugs are plain to see and happen under replicable conditions. Some bugs occur sporadically, leaving only traces (or logs) to examine. Some bugs occur in a specific environment only, usually a production environment that is inherently unsuitable for invasive debugging techniques. Some bugs mysteriously disappear as soon as someone tries to track them down, and pop up again when no one is watching.
Like weed, different kinds of bugs have to be treated differently.
Replicable bugs
When I worked in tech support, any unexpected behavior that customers reported was treated with the same first step: We asked the customer to provide steps to replicate the behavior.
For any unexpected behavior, being replicable has a few advantages:
- All involved parties (usually customer, tech support, and engineering) can agree on the observed behavior
- If everyone can replicate the behavior at their end, it is easier to discuss the problem
- Once a behavior is replicable at will, it can be extensively tested and examined
- Traditional debugging techniques (debugger, ad-hoc logging a.k.a. “judiciously placed print statements”, etc) work well
- A fix can be confirmed immediately (especially, if you have put up guardrails in form of added tests)
With a replicable bug, troubleshooting is comparatively straightforward:
- Starting from the available information about the bug, locate the code that fails.
- Determine the context as precisely as possible. A given function can be called from various places. Try to identify the exact call chain through stack traces and/or log output, to collect as much as possible about the context that leads to the wrong behavior.
- Now throw all code debugging techniques on the problem: Inspect the code; build a mental model of what might go wrong; then place
log.Printf()orwhat.Happens()statements or fire up Delve to inspect places where you need clarity.
At any troubleshooting stage, don't hesitate to discuss the bug with others. If you cannot get hold of anyone, your favorite AI code assistant.
Sporadic bugs
Infrequently occurring bugs can be quite nasty. Without a deterministic repro case, identifying the erroneous code is next to impossible. Therefore, turning a sporadic bug into a replicable bug is paramount.
Use these techniques to zero in on the bug:
- Ask the bug reporter for any patterns they have, or might have, encountered. Also, try to identify any sort of recurring pattern by yourself.
- Examine all log output and other observability information you can get hold of.
- Look for logging patterns that deviate from the “normal” patterns you are used to seeing during typical activity.
- Verify if metrics indicate unnormal conditions such as nearly-out-of-memory situations or unusual allocation of resource handles (files, databases,…).
- Send out your spies.
- In production, raise the log levels as high as your operators are comfortable with. (Remember, you may need to capture logs over a longer period of time, until the next irregular bug event hits.)
- If you happen to spot the sporadic error in non-production environments, add more ad-hoc logging statements.
- If the bug manifests itself through a particular error message, work your way back from the source of the error to possible conditions that trigger the error, and test them out until the error starts occurring regularly under a given test condition.
At this stage, you have turned the sporadic bug into a replicable bug and can continue with the aforementioned techniques to troubleshoot replicable bugs.
Heisenbugs
A particularly unpleasant form of sporadic bugs are Heisenbugs. The name is a reference to Werner Heisenberg, a German theoretical physicist who introduced the uncertainty principle. In layman's terms, this principle says that it is not possible to measure certain pairs of physical properties of an elementary particle, such as position and momentum, at the same time, because the observer disturbs the particle simply by observing it.
In an analogy to the uncertainty principle, Heisenbugs are bugs that seem to disappear or alter their behavior when someone attempts to replicate them at will.
For example, inserting log statements into time-sensitive code may alter the timing so that the erroneous behavior vanishes. When removing the additional log statements, the behavior returns.
So to track down a Heisenbug, you have to replace any invasive debugging techniques with passive observation, code examination, and a lot of thinking. (As of this writing, I have no information about how good LLMs are at pinning down a Heisenbug when given the code and a description of the bug's appearance and known circumstances.)
Concurrency bugs
Concurrency adds a new dimension to code behavior. When code can split into multiple lines of execution, timing is suddenly much more relevant than in single-threaded code. For example, concurrent code can write into the same data entity at the same time (called a data race), or two goroutines could lock each other, waiting for each other's resource to be unlocked.
Debugging concurrent code can be complicated2. There are certainly more Heisenbugs to be found, as any invasive observation changes the timing (subtly if you insert ad-hoc logging statements, and not so subtly if you make a goroutine halt at a breakpoint while other gorouintes continue to run).
Here are some techniques to track down concurrency bugs—:
- Enable the data race detector to identify data races in your code.
- Use pprof to generate profiles of CPU, memory, goroutines, allocations, blocking on synchronization, or mutex contention.
- Use
go tool traceto view trace filed that you can generate with either of:runtime/trace.Start(), thenet/http/pprofpackage, or passing the-traceflag togo test. - Simulate a single-threaded enviromnent by calling
runtime.GOMAXPROCS(1)or setting the environment variable GOMAXPROCS to 1.
Delve, Go's go-to debugger
I mentioned Delve earlier, as it is easily the most-used debugger for Go. If your Go IDE has an integrated debugger, it's probably Delve.
With Delve, you can step through code of apps or tests by simply calling either
dlv debug [<path-to-main-package>]
or
dlv test [<path-to-package-with-tests>]
to start Delve's REPL. From there, you can add breakpoints and continue execution to the first breakpoint, step through lines of code, or inspect variables.
I won't go into details about Delve, as this can easily fill a few more blog articles. For more detailed information on how to set up and use Delve, check out the documentation via pkg.go.dev and my Delve cheat sheet in the Spotlights section.
Debugging by bisecting the Git history
Stepping through code with a debugger can be tedious, especially if you have no clear idea where the bug hides, because the bug doesn't result in a clear error message with a stack trace and line numbers.
Did you know that your version control system—Git, to be precise—can help narrow down such a bug?
The technique is called git bisect and here is how it works.
Any bug got introduced between two commits: One where the code still worked fine, and one where the code started failing. (Except for faulty code at the first commit, but then, you wouldn't have that much code to inspect.) So if you systematically test older versions of your code until you find those two commits, you can quickly isolate the changes that are responsible for the bug.
Git provides the bisect command for this purpose. All you need is a “bad” commit; that is, a commit that definitely contains the bug, and a “good” commit that is known to not contain the bug.
The bisect process then selects a commit in the middle between the good and the bad commit and checks it out. Then you compile and test the code, and depending on the result, you mark this commit as either “good” or “bad”. Now you have a new, smaller range of commits between a good and a bad one.
Then bisect selects another commit in this range, and the process repeats until the first bad commit is found.
Now you can inspect the diff to the previous commit to get the parts of the code to analyze.
A nice aspect of the bisecting process is that you don't need to worry about picking good and bad commits that are far away of each other. Because each bisect step cuts the range of commits in half, you only need log2(n) steps to find the first bad commit in a range of n commits. For, say, 100 commits between the initial “good” and “bad” commits, you would need 7 rounds of bisecting.
Read more about the bisect command in the git-bisect Documentation.
Bonus tip: GoTutor—a low-barrier entry to debugging
Firing up a debugger to step through code and traverse deep data structures can be daunting for newcomers. Meet GoTutor, an online Go debugger that lets the user step through the code and shows how variables, goroutines, and stack frames come and go.
Here is a screenshot of a sample debugging session:
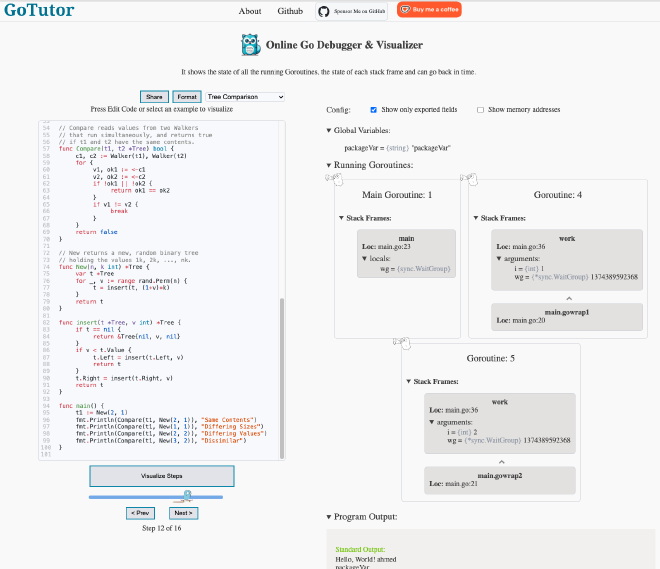
Did you notice the Prev and Next buttons? You can actually step backwards through the code and repeat steps as often as you want. An easy but effective way of deepening the understanding of an execution flow.
Isn't that a fun way to learn debugging?
FAQ: Debunking debugging myths, and other
What are some common debugging mistakes?
Here are five common mistakes developers make when debugging:
- Not zooming out. Don't get caught up in code details without understanding the bigger picture.
- Failing to use appropriate debugging tools. Depending on the context, you might only need a few log statements, or you have to use the debugger's full power.
- Rushing to find a solution. The pressure to fix bugs quickly can lead to hasty decisions and overlooking important details. You might end up just fixing symptoms rather than the root cause. Or you might debug endlessly because the quick fixed don't work.
- Not testing code changes thoroughly. Verify that your fixes don't introduce new bugs or break existing functionality.
- Overlooking version control. Commit frequently enough to have fine-grained rollback options and make bisecting effective.
Debuggers are for debugging, correct?
Debuggers are designed for debugging, but this doesn't mean you can't use them for other purposes. For example, if you are faced with an unknown and fairly complex (or just badly written) codebase, a debugger can help you dig deep into the unknown code and examine what a particular functions is doing or how a particular data structure is used.
Can I automate debugging?
While debugging is inherently a manual activity (see also the section on test-driven development), you can automate certain aspects of it.
Your code, for example, can be a valuable assistant for debugging. Packages like runtime and runtime/debug can help reveal internals of your app while it's running.
Use cases include:
- Dumping the stack trace of a goroutine
- Triggering garbage collection, including returning memory to the OS
- Inspecting various counters such as the number of running goroutines, available CPUs, or CGO calls
- Retrieving memory statistics, memory profiles, or mutex profiles
- Changing certain limits such as the maximum number of OS threads, a soft memory limit, or the maximum size of a goroutine's stack
Using a flag or a feature flag, you can switch debugging commands on or off without recompiling or even restarting the app. A great way to (semi-)automate debugging.
Which debuggers can I use with Go?
First of all, there is Delve, the aforementioned Go-native debugger. It's the go-to debugger for most situations, well integrated with IDEs and code editors. However, if you need to debug on a platform that Delve doesn't support, the GNU Debugger, or GDB, is a useful alternative, even though it is not that integrated with Go as Delve is.
Why are software defects called “bug”?
The term “bug” for defects goes back to engineering jargon of the 1870s, well before computer software as we know it now was invented.
Fun fact: In 1947, a hardware bug in a mechanical computer was identified as a real, physical moth trapped in a relais. (See the above link for more details.)
Boost your debugging skills
Debugging requires knowledge about the tools and techniques to use, and I hope this article provides enough information to give you a quick start. Debugging skills deepen with practicing and experience, and if you want to go deeper into the fundamentals of debugging, Matt Boyle has an excellent course about debugging with Go at ByteSizeGo.
Here’s the best part: Use the coupon code APPLIEDGO40 at checkout to get 40% off the regular price—plus, you’ll be supporting AppliedGo in the process! ❤️
(Affiliate Link)
Links
- Package
runtime - Package
runtime/debug - Package
what - Delve
- Delve cheat sheet
- The data race detector
- Werner Heisenberg
- Uncertainty principle
- Heisenbug
- The pprof tool
- Git bisect
- [Do you use a debugger? | Sandor Dargo's Blog][sandor-debugger]
- The SOLID principle
- OWASP's Logging Cheat Sheet
- GoTutor
- Once In A Blue Moon (Peter Finger)
Happy coding!
Once in a blue moon
This is completely unrelated, but the exceptional guitarist Peter Finger wrote a gorgeous piece called Once In A Blue Moon. (All pieces on the album Blue Moon are gorgeous, by the way. Let the music take over and watch your stress wrinkles melt away.) ↩︎
Complicated vs complex
I define the terms “complicated” and “complex” in the following way, based on the Cynefin framework:
- Complicated refers to the known unknown: a difficult but well-defined system
- Complex refers to the unknown unknown: a system with unpredictable properties and emergent behavior
So although debugging can become complicated, remember you are troubleshooting a well-defined system that adheres to rules such as the language specification. Even Heisenbugs do not make an app unpredictable in theory, even though in practice it is rarely possible to gain a complete understanding of the whole system. ↩︎