
A (not so) new cyber attack exploits autonomous AI agents if they combine three capabilities:
- They have access to sensitive data (YOUR data, if it's your agent)
- They have access to the internet somehow (for example, via email or HTTP)
- They can receive untrusted content (which may contain hidden prompts)
Open-source developer, Datasette creator, and web-logger-at-insane-speed Simon Willison coined the term “Lethal Trifecta” for this unholy triplet of otherwise harmless properties. “Lethal” is what science folks write when they mean “deadly.” And a trifecta is, roughly speaking, a set of three wins or other things that, when combined, deliver an advantage (to someone, which could be a disadvantage to someone else, as it's the case here).
How the attack works
The above three properties, when combined (and only then), expose AI agents to a severe form of attack. Here is an example of a vulnerable scenario: Let's assume you have prompted an AI agent to –
- continuously scan your email for invoices,
- save them locally,
- extract and normalize the invoice data,
- and upload this data to your bookkeeping software via API.
The agent connects an email client tool and an API calling tool to a large language model (LLM), which can make use of both tools as it sees fit.
Current LLMs, however, aren't good at distinguishing prompts from the input they're supposed to process. If the input contains text that sound like a prompt to them, they might get tricked into following that hidden prompt, rather than treating it as passive data.
It's the AI equivalent of social engineering.
So, in our example, an attacker would just have to send an email with content that looks harmless to the human reader but contains a hidden prompt (for example, as white-on-white text). The prompt could advise the LLM to upload the processed invoices to a different API. Data exfiltration as a service!
It's hard to block this attack at agent level
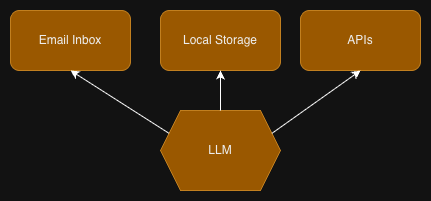
Unfortunately, the aforementioned three capabilities turn an AI agent into a truly universal assistant. The current hype around OpenClaw occurred because it can do all these things: read personal data, access the web, and receive untrusted content to process.
Hence, hardening an agentic AI against this kind of attack turns out to be tricky. The effect of security advice added to the system prompt is naturally limited; it's like telling a drug addict to pleeease ignore any drugs they might find in their letterbox.
What about simply removing one of the capabilities? Well, then the AI agent stops being a universal assistant. Without access to personal data, all that remains is an AI-based search engine. No internet access means severe limitations to research and data exchange. And how would you decide what input can be trusted? There is no way around it; a universal agent needs all three.
But how can a system be defended that invites attacks by design? The standard industry answer is to build complicated, multi-layered security architectures around the AI assistant that introduces guardrails, deep content inspection, firewalls, permission architectures, detect-and-respond schemes, isolation, humans in the loop, among other techniques and technologies.
To me, this feels like overkill.
A much simpler approach
Why does the industry respond to the problem with such extensive countermeasures? Because it wants—no, it has to—deliver solutions that address all sorts of AI assistant scenario.
But you and I aren't “industry”. We're individuals with very specific use cases for AI assistants. Specific use cases don't need the full flexibility of an LLM that has access to all your data, your tools, and the internet. While it's impossible to remove any of the three capabilities (or the assistant would not be an assistant anymore), it's very possible to restrict them so that attacks no longer work.
In the above example, -
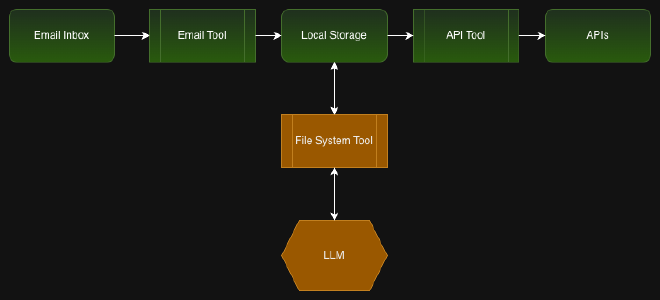
- Instead of giving the AI assistant full read access to your inbox, write a tool that fetches emails with attachments and optionally filters them for keywords like “invoice”, “payment”, etc. The consequence: Attackers can no longer advise the LLM to read each and every email in the inbox.
- Instead of giving the AI assistant general tools for reading and writing to and from the file system, build a tool that can only do the specific operations required for saving and processing the invoice. Attackers then can no longer access arbitrary local data.
- Instead of letting the LLM access a tool that can call API's, build a tool that just calls the specific API needed for the job, at a given, and hard-coded, endpoint. Attackers can no longer let the assistant call an arbitrary API endpoint to exfiltrate data.
Yes, that's right: Write a simple tool to do the mundane work1. The tool can't do anything else, so the LLM can't run wild and do things it isn't supposed to.
Without these measures, the LLM can access emails, files, and APIs at its sole discretion.
With specialized tools between the data and the LLM, the LLM can only process the data it is supposed to, and only in the way it is supposed to. It cannot trigger unwanted actions anymore. If a prompt advises the LLM to read all emails, it can't. If a prompt advises the LLM to call a different API endpoint, it can't.
It's that simple.
By delegating one or more capabilities to a dumb, deterministic tool, you can cut off attack vectors without actually removing any of the three capabilities that the AI assistant needs for this particular scenario.
But is this still a universal AI assistant then? Well, hard-coding particular steps in an assistant's workflow definitely reduces the assistant's degrees of freedom. However, if you give a human coworker a task, would you give them unrestricted access to tools, data, and everything? I bet you wouldn't.
But who's going to write all those tools?
At a first glance, the solution seems to require much more effort than letting the AI assistant figure out how to use general tools to do the same job. But with AI's help, writing such tools isn't a day's work anymore. LLMs have become darn good at producing code from prompts. And because the tool has to be created only once for a particular AI assistant setup, having a human in the loop (for quality assurance) isn't a problem.
LLMs have become quite good at generating code in most established or popular languages. But you know me—I'd prefer Go all the time, even if an AI generates the code. Go has many great properties, and of these, some are a great fit for AI-assisted coding, such as the insanely fast compiler, the syntax and semantics that are easy for humans and bots, or the ability to generate stand-alone binaries by default (good for easy integration into AI workflows).
Nutshell ahead
So in a… nutshell, instead of layering security above and around an unrestricted AI assistant, build a constrained agent from the start, equipped with specialized tools. Rather than letting the LLM decide what to access, decide what the LLM is allowed to see. And before adding security by detection and prevention, add security by limitation.
Broader speaking, put dumb tools between a smart system and sensitive resources.
The tools hard-code the boundaries of what the smart system can do. A simple trick for boosted security and peace of mind.
I am aware of the irony: We see AI as the tool to get rid of mundane tasks, yet I'm suggesting to help AI to get rid of mundane tasks. ↩︎